Elasticsearch 保留字符查询如:*、$、: 等
一个非常简单的需求,需要在 ES 中去匹配 IPV6 的 2409:8a10:* 段的数据,看看如何查询
实现
1 | GET logstash-nginx-*/doc/_search |
这里的重点是 """2409\:8a10\:*""" 也可以写成 "2409\\:8a10\\:*",其他的符号也可按此类推即可
最后效果: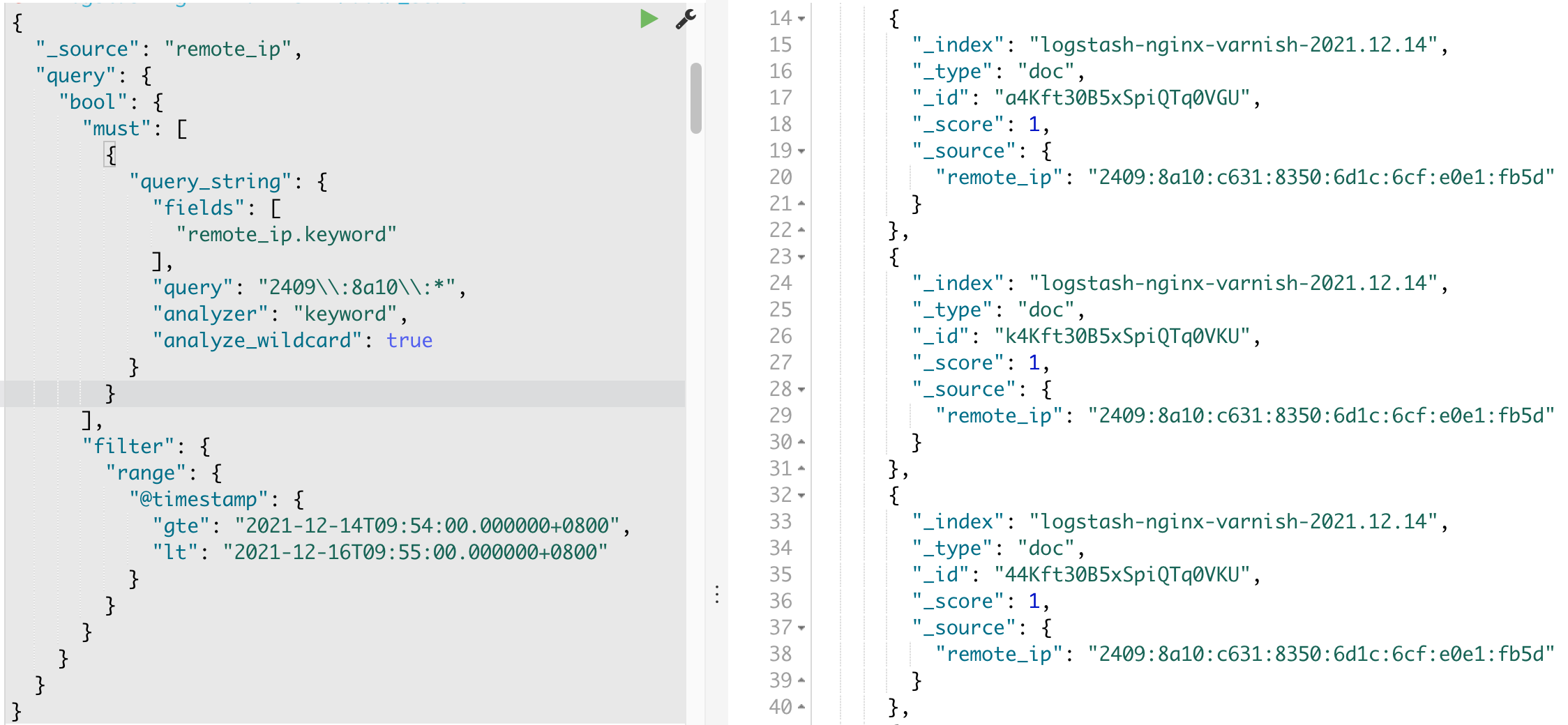
一个非常简单的需求,需要在 ES 中去匹配 IPV6 的 2409:8a10:* 段的数据,看看如何查询
1 | GET logstash-nginx-*/doc/_search |
这里的重点是 """2409\:8a10\:*""" 也可以写成 "2409\\:8a10\\:*",其他的符号也可按此类推即可
最后效果:
在 Python 中需要热加载是非常简单的,以 Sanic 为例只需要设置 auto_reload=True,但是在 Gin 中没有内置相应的功能,这里我们可以利用 Go 中的一些其他包实现,即更改源码,保存后,自动触发更新,浏览器上刷新即可。免去了杀进程、重新启动之苦
试了下 github.com/gravityblast/fresh 还觉得不错
安装:
1 | go get github.com/pilu/fresh |
使用:
1 | fresh |
记录一下其他实现框架
Air:https://github.com/cosmtrek/air
Bee:https://github.com/beego/bee
Realize:https://github.com/oxequa/realize
Gin:https://github.com/codegangsta/gin
gowatch:https://github.com/silenceper/gowatch
题外话:
在安装非项目使用的包时如:fresh,最好是不要在项目根目录下进行 go get 或者会被写入到项目的 go.mod 中
type 定义的结构体和接口都是类型
在 Go 中,如果一个名字以大写字母开头,那么它就是已导出的,在导入一个包时,你只能引用其中已导出的名字。任何未导出的名字在该包外均无法访问
类似其他语言 Public 与 Private 修饰符
Go 的返回值可被命名,它们会被视作定义在函数顶部的变量。返回值的名称应当具有一定的意义,它可以作为文档使用。没有参数的 return 语句返回已命名的返回值。也就是直接返回
函数中,简洁赋值语句:= 可在类型明确的地方代替 var 声明
函数外的每个语句都必须以关键字开始(var, func 等等),因此 := 结构不能在函数外使用
没有明确初始值的变量声明会被赋予它们的零值,0、false、""(空字符串)
使用 const 关键字声明,常量不能用:= 语法声明
defer 语句会将函数推迟到外层函数返回之后执行,推迟调用的函数其参数会立即求值,但直到外层函数返回前该函数都不会被调用
推迟的函数调用会被压入一个栈中。当外层函数返回时,被推迟的函数会按照后进先出的顺序调用可以看做是倒序执行
指针保存了值的内存地址
它会选择一个半开区间,包括第一个元素,但排除最后一个元素
切片并不存储任何数据,它只是描述了底层数组中的一段。更改切片的元素会修改其底层数组中对应的元素。与它共享底层数组的切片都会观测到这些修改
有了匿名函数,就可以在函数中再定义函数(函数嵌套),定义的这个匿名函数,也可以称为内部函数。更重要的是,在函数内定义的内部函数,可以使用外部函数的变量等,这种方式也称为闭包
方法就是一类带特殊的接收者参数的函数
接收者的类型定义和方法声明必须在同一包内;不能为内建类型声明方法
使用指针接收者的原因有二:
首先,方法能够修改其接收者指向的值。
其次,这样可以避免在每次调用方法时复制该值。若值的类型为大型结构体时,这样做会更加高效
通常来说,所有给定类型的方法都应该有值或指针接收者,但并不应该二者混用
接口类型是由一组方法签名定义的集合
类型通过实现一个接口的所有方法来实现该接口。既然无需专门显式声明,也就没有 “implements” 关键字
隐式接口从接口的实现中解耦了定义,这样接口的实现可以出现在任何包中,无需提前准备
因此,也就无需在每一个实现上增加新的接口名称,这样同时也鼓励了明确的接口定义
未完待续…
国内的 PYPI 源也挺多的,经过实际使用下来,还是觉得华为的 PYPI 源包的版本最为齐全,推荐用华为的源进行加速
运行以下命令使用华为源:
1 | pip install -r requirements.txt --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple |
或者
1 | pip install --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple sanic |
通过上面的方式安装单个包
Pip 的配置文件为用户根目录下的:~/.pip/pip.conf(Windows 路径为:C:\Users\<UserName>\pip\pip.ini), 您可以配置如下内容:
1 | [global] |
其他国内镜像源:
1 | 阿里云:http://mirrors.aliyun.com/pypi/simple/ |
个人推荐使用华为的 Alpine 源,通过我的测试华为的源最为齐全
1 | sed -i 's/dl-cdn.alpinelinux.org/repo.huaweicloud.com/g' /etc/apk/repositories |
1 | sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories |
1 | sed -i 's/dl-cdn.alpinelinux.org/mirrors.ustc.edu.cn/g' /etc/apk/repositories |
1 | sed -i 's/dl-cdn.alpinelinux.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apk/repositories |
1 | RUN sed -i 's/dl-cdn.alpinelinux.org/repo.huaweicloud.com/g' /etc/apk/repositories |
最近开发 Python 一直在用 Sanic,感觉还不错;看看如何将 Sanic 部署到 Docker 中并用 Supervisor 来守护
这里利用 Python 3.9 来构建基础镜像
1 | FROM python:3.9-alpine |
这里利用华为的 alpine 源和 pypi 源
1 | [unix_http_server] |
题外话:
容器运行 Supervisor 记得设置 nodaemon=true,或则会出现 Unlinking stale socket /var/run/supervisor.sock
因为 Supervisor 默认是 deamon 模式,启动命令结束后 Supervisor 会在后台运行,而容器运行启动命令返回 0 后自己关闭了,导致一直出现无法运行的现象
此错误是利用 python:3.9-alpine 在打包 Docker 镜像时遇到的
1 | c/_cffi_backend.c:15:10: fatal error: ffi.h: No such file or directory |
修复
1 | apk add --no-cache libffi-dev |
在 Ubuntu 和 Centos 中应该
1 | apt-get install libffi-dev |
错误:
1 | pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out. |
修复:
1 | pip3 install --default-timeout=1000 --no-cache-dir -r requirements.txt |
或者是利用国内的 pypi 源
一般在项目中我们不太会去注意 SQL 注入的问题,因为我们会使用 ORM,而 ORM 在实现的过程中也会帮我做 SQL 注入过滤;但有的时候 ORM 没法满足我们的需求,这时可能就会手撸原生 SQL 来执行
注意!!极其不建议使用拼接 sql 语句,这样很容易引起 sql 注入!!
如果必须要自己拼接 sql 语句,请使用 mysql.escape 方法;或者利用正则来对输入参数进行过滤。以 Python为例利用 re.compile 生成正则表达式,然后利用 re.search 进行判断,实现如下:
1 | pattern = re.compile( |
也有一种直接简单粗暴的方法,那就是直接过滤关键字:
1 | pattern = r"\b(exec|insert|union|select|drop|grant|alter|delete|update|count|chr|mid|truncate|delclare)\b|(;)" |
常用 SQL 注入 payload
1 | --- 通用SQL注入payload |
Python 中的 Webservice 客户端 suds 常用的有两个包
目前选择的是 suds,安装
1 | pip install suds |
具体实现如下:
1 | import xml.etree.ElementTree as ET |
先看看看 client 中的方法
1 | Suds ( https://fedorahosted.org/suds/ ) version: 1.0.0 |
如上所示 CST_INF_JOBCODE_OUT 方法有 3 个参数而且都是 string 类型,这里重点说说 REQUEST_DATA,原生请求 Xml
1 | <soapenv:Envelope |
对于 REQUEST_DATA 中的 CDATA 包裹部分应该选择原样传入
1 | <![CDATA[ |
最后是对 xml 的解析可以利用 ElementTree,具体可以参考