Vue 或者 NodeJs 中将 Bytes 格式化成 KB、MB、GB、TB
自适应将 Bytes 格式化为可读性更高的单位
1 | formatSize(bytes) { |
效果图如下: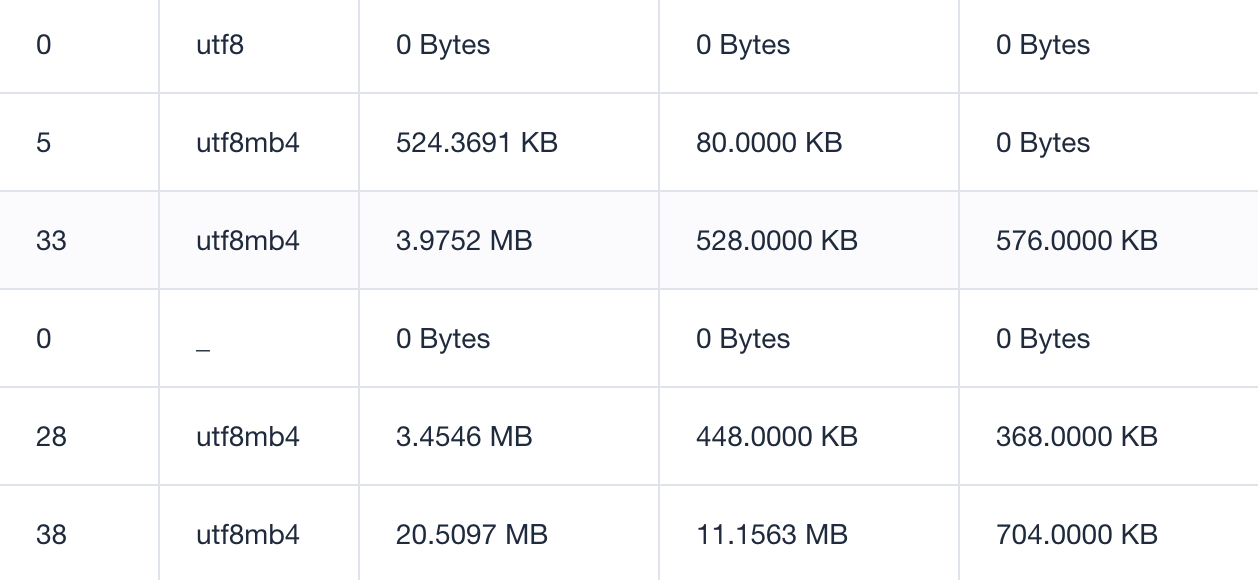
自适应将 Bytes 格式化为可读性更高的单位
1 | formatSize(bytes) { |
效果图如下:
1 | select(func.count()) |
1 | func.COUNT( |
1 | select(["*"]) |
如果要使用 not exists 只需要在 exists() 前加上 ~ 变成 ~exists()
1 | conditions = [] |
1 | user.update() |
1 | # 升序 |
未完待续…
GO 的环境安装可以使用 brew
1 | brew install go |
接下来只需要配置一下对应的环境信息
1 | export GOPATH=/Users/jakehu/Documents/go |
利用 goimports 格式化 import 排序使用
1 | go install -v golang.org/x/tools/cmd/goimports@latest |
利用 golangci-lint 做静态代码检查
1 | go install -v github.com/golangci/golangci-lint/cmd/golangci-lint@latest |
vscode 配置
1 | // GO |
Curator 是 Elastic 官方发布的一个管理 Elasticsearch 索引的工具,可以完成许多索引生命周期的管理工作,例如清理创建时间超过 7 天的索引、每天定时备份指定的索引、定时将索引从热节点迁移至冷节点等等。
如果没有安装 pip 先安装 pip
1 | wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo |
利用阿里的 epel 源
1 | yum -y install python-pip |
Curator 本身是基于 Python 实现,所以可以使用 pip 安装
1 | pip install elasticsearch-curator |
升级
1 | pip install -U elasticsearch-curator |
查看版本
1 | # curator --version |
新建配置文件 curator.yml,具体格式可以参考官方默认的配置文件
1 |
|
新建执行动作文件 delete_indices.yml,比如我执行删除7天前的索引
1 |
|
1 | curator --config /etc/curator/config.yml /etc/curator/action/delete_indices.yml |
执行结果如下: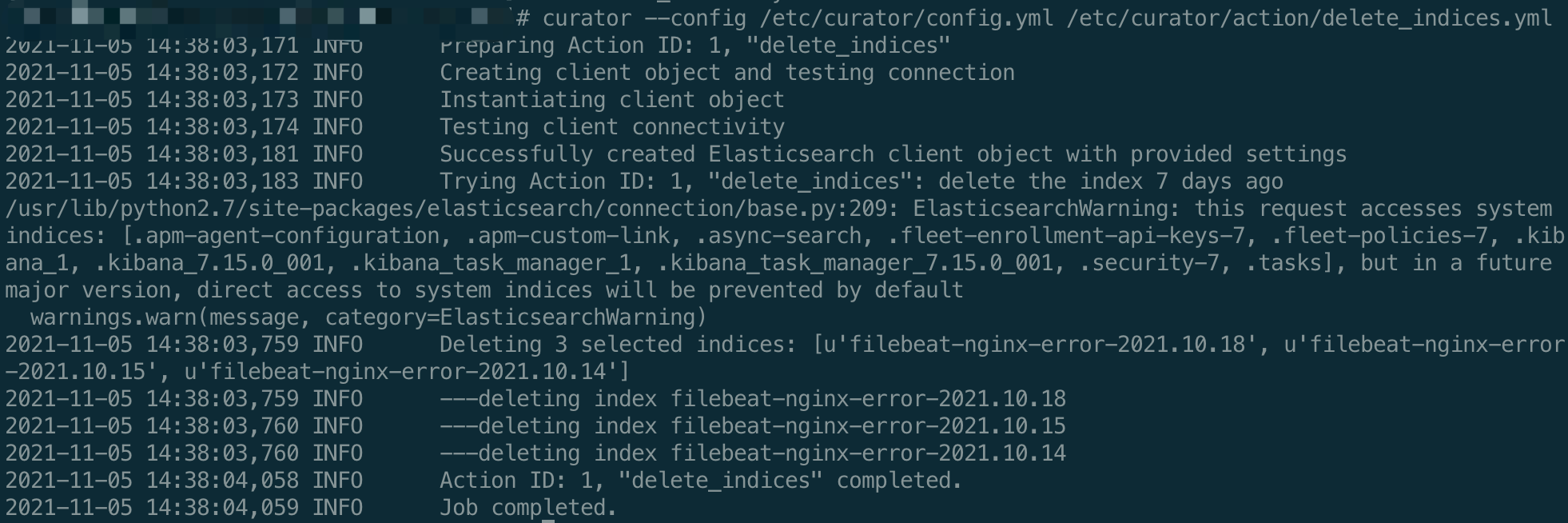
未完待续
全局安装 flake8
1 | /usr/local/bin/python3 -m pip install -U flake8 |
全局安装 black
1 | /usr/local/bin/python3 -m pip install -U black |
1 | "python.languageServer": "Pylance", |
flake8 和 black 可选参数:
1 | "python.linting.flake8Args": [ |
排序 import 语句
1 | /usr/local/bin/python3 -m pip install -U isort |
配置
1 | "[python]": { |
也可以配置用于全局
1 | "editor.codeActionsOnSave": { |
在一些软件中如 ES,时间格式都是 UTC 时间格式。记一记如何将 UTC 时间格式转换为本地北京时间格式。
原理很简单:将UTC转化为datetime时间格式->将转化的datetime时间加8小时->格式化为想要的格式
1 | import datetime |
ELK 对于日志管理来说毫无疑问是最好的选择,但有的时候觉得 Logstash 比较的笨重,相反 Filebeat 也不失为一个好的选择。
此次安装的版本为 7.15.0
对于几个组件的安装都是非常的简单,可以直接利用官方打好的包就好
安装时建议通过 RPM 包安装,这样能固定版本减少一些兼容性问题如:
1 | wget https://artifacts.elastic.co/downloads/kibana/kibana-7.15.0-x86_64.rpm |
如果只是单机版的话 Elasticsearch 配置倒是不用过多修改,接下来配置一下 Elasticsearch 开启密码访问就可以了
1 | xpack.security.enabled: true # 普通的安全设置 |
最后再通过下面命令设置各个用户的密码
1 | $ /usr/share/elasticsearch/bin/elasticsearch-setup-passwords auto |
上面命令会设置各个内置用户的密码
Kibana 只需要配置如下几个项目即可
1 | server.port: 5601 # 端口 |
1 | output.elasticsearch: |
对于 Filebeat 的设置,这里的 username 需要用 elastic 用户。如果用 beats_system 用户的话会提示 403 无权限。
具体可以参考:Security error with beats_system account and Filebeat with system module
以 nginx 为例打开 nginx.access 和 nginx.error
1 | vi /etc/filebeat/modules.d/nginx.yml |
进入 Kibana 管理页面,新建索引Management->Stack Management->索引模式->创建索引模式
配置到索引时就已经可以在 Kibana 中看到有 nginx 默认的日志进来,但如果我们有自定义的日志格式,就需要用到 Pipeline
Pipeline 所存放的位置 /usr/share/filebeat/module/nginx/access/ingest/pipeline.yml
也可通过开发工具查询 GET _ingest/pipeline/filebeat-7.15.0-nginx-access-pipeline
最近遇到一个需求,每 60S 刷新数据库数据到 Redis 缓存中,但应用又不止一个进程。此需求中对原子性并无太大的要求,只是如果每次只有一个进程执行,那么数据库的压力就会小很多。
于是想到用分布式锁来解决这个问题,最终选择了通过 Redis 来实现。
关于 Redis 实现分布式锁可以查看下面的文章:
分布式锁的实现之 redis 篇
在众多的官方推荐的分布式锁客户端中,我选择了 Aioredlock
1 | async def aioredlock(): |
通过上面代码就能实现,需求所要求
在使用 Tortoise Orm 的过程中发现数据库自动插入、更新的时间是 UTC 时区时间,通过官网文档发现可以在连接时对时区进行设置
通过连接配置来修改时区,默认情况下的连接配置
1 | register_tortoise( |
如果需要修改配置,则不能用 db_url 模式连接需改为 config 模式连接,配置如下
1 | register_tortoise( |
通过以上配置就能将数据库时区设置为上海时区
当原子系统很多 (非微服务),而且各个原子系统之间需要相互调用,这时就需要保证两个系统之间的认证、以及数据加密。
这个时候就需要用到对称加解密了
对于如何选择合适的加密算法,可以参考一下下面这篇文章
如何选择 AES 加密模式(CBC ECB CTR OCB CFB)?
最后我选择了两种方式分别来测试和实现 CBC、OCB
另外 pycrypto 已经不再安全,建议使用 pycryptodome,它是 pycrypto 的分支,在安全性方面有较大提升。
1 | pip install pycryptodome |
1 | import json |
结果:
1 | 密文: {"iv": "K8xL41sI3UoXaeWohUuZEA==", "ciphertext": "fLGcOq43vTZc9x3HX8Q9Nv82cwVT6WNTj5mcpuPEckw="} |
1 | import json |
结果:
1 | 密文: {"nonce": "9Wd6sA1QGSdjXHu1zACA", "header": "aGVhZGVy", "ciphertext": "tyaCFrLuriy6F3xJqs0CehNWe3g7", "tag": "IqDrP9zX00aZMRe7DuCRzQ=="} |